
- Find, visualize, and download linguistic annotations
- Contributing linguistic annotations to CDLI
- Annotations
- Automated annotation
Find, visualize, and download linguistic annotations
To find text annotations in CDLI, you can do an empty search and then use the filters to select only entries which have annotations.

It is not possible to search through the annotations on the normal search. Annotations can be searched using the Corpus Search (this service is awaiting maintenance and will be available some time later).
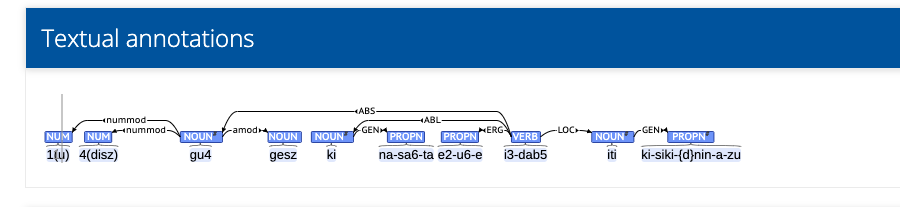
Once you see the results, you can visit the page of an artifact you would like to see the annotations of. Simply open the tab "Textual annotations" to see the parse tree displayed.
To download the annotations, you can either use the export button on the search results page or on an artifact's page.

 You can download the data in CDLI-CoNLL and CoNLL-U formats.
You can download the data in CDLI-CoNLL and CoNLL-U formats.
Contributing linguistic annotations to CDLI
Before starting, make sure you have a registered account and logged into the cdli website. If you do not have an account, register here: register, and email the editorial team cdli (a) ox.ac.uk so they can activate your crowdsourcing privilege.
Data validation
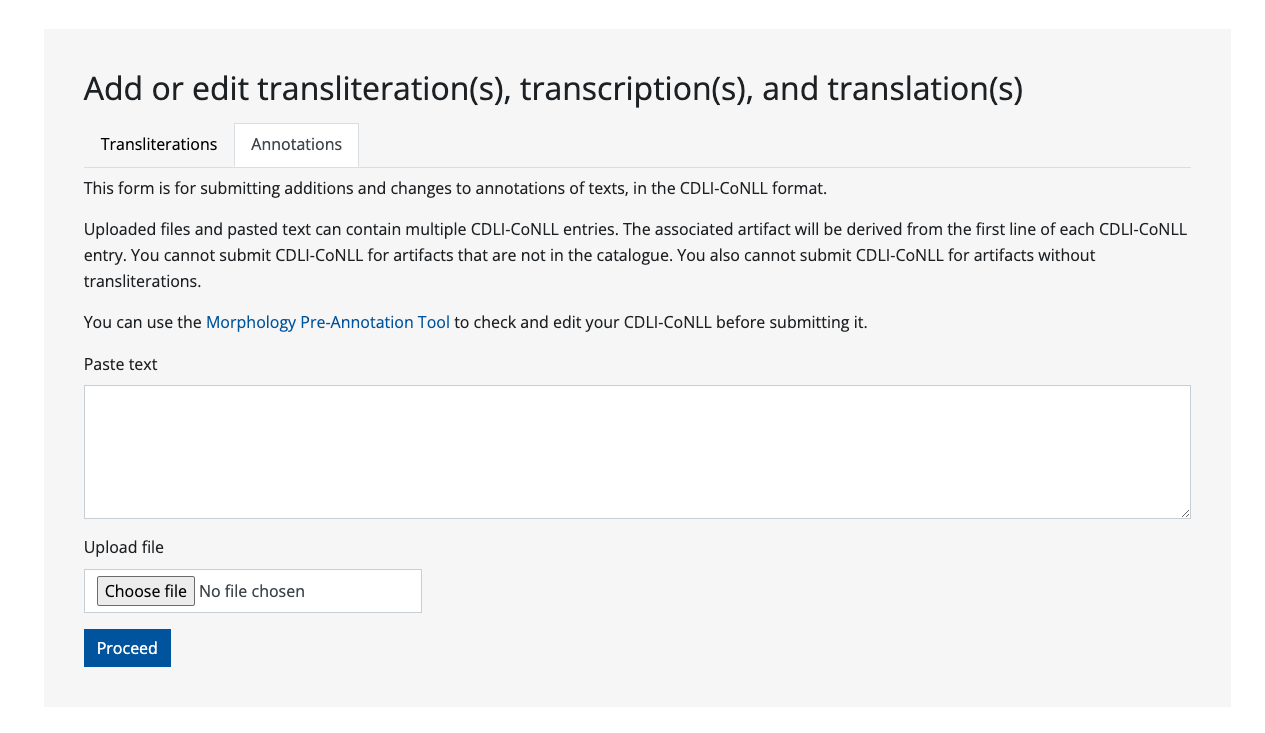
You can validate your data when submitting it. There is always a verification step before final submission of the data and it is intended to be used as a validation tool too. After seeing the validation results, you can simply cancel your submisssion. You can use this process to validate your data even if you don't intend to submit it to CDLI. We also have a validation page which is separate of the submission process. Annotations can be pasted in a text field or uploaded as a file, and the data can contain one or more text.
Submitting data
Before submitting any text annotation, an associated metadata entry must exist and it must also have text attached. After logging in, you can submit individual new entries or groups of them and the associated texts at the submit text and annotation page.
If you would like to add or edit annotations for a single artifact, you can do so from its page. Click on the "Edit" button then on add / edit Text of Annotation.
Submission review
Once you have submitted changes, they will be in the review queue. An editor should be approving it in the next seven days. Once approved, the annotation will appear instantly on the artifact page.
Automated update of annotations
When the transliteration of a text is being updated, the tool CoNLL-Merge will attempt to correct the annotation of the text automatically. This requires a human to check the result. Until the automated correction of the annotation has been verified, a tag will appear by the artifact to announce this fact to users.

Annotations
Formats
CoNLL formats are tab separated values files where each column is used for a different type of information.
CDLI-CoNLL
CDLI-CoNLL is our in-house CoNLL format which can encode more information than CoNLL-U for now. The format shoacases 7 columns instead of 10 and an additional comment line, when necessary, to indicate automated annotations were made.
Comments
First, every text starts with # new_text = PXXXXXX so we can always trace which text this relates to.
Secondly, the line #automated annotation: POS; NE; lemmata; morph; syntax can appear, with items in the list based on which annotation was created automatically. When the annotation is reviewed manually by an editor, this comment line is removed entirely. If then automated annotation of syntax would be applied, #automated annotation: syntax would be added. The list of possible types of annotations are:
-
POS
-
NE
-
lemmata (this includes the sense)
-
morph
-
syntax
This list might be updated based on practice.
Headings
# ID FORM SEGM XPOSTAG HEAD DEPREL MISC
- ID: all information about the surface, column, line and token (o.col1.1.1; o.1.1 if there is no column). Only the column number is optional.
- FROM: token from text, ATF transliteration
- SEGM: normalized form of the token
- XPOSTAG: ORACC ETCSRI morphological tags based on the segmentation and using POS tag or named entity tag instead of "STEM" for the stem (eg.: GN.ABL)
- HEAD: id of token that is the verb for which this token is a subject or object
- DEPREL: relationship with verb as subject, direct object or indirect object (nsbj/dobj/iobj)
- MISC: semantic role of this word, eg. "seller"
CoNLL-U
The coNLL-U format is used as an exchange format but we store the annotations in CDLI-CoNLL format because CoNLL-U cannot store all the rich morphological information of the Sumerian language.
#ID FORM LEMMA UPOSTAG XPOSTAG FEATS HEAD DEPREL DEPS MISC
ConLL-U field descriptions based on the Universal Dependencies website:
- ID: Word index, integer starting at 1 for each new sentence; may be a range for multi-word tokens; may be a decimal number for empty nodes.
- FORM: Word form or punctuation symbol.
- LEMMA: Lemma or stem of word form.
- UPOSTAG: Universal Dependencies (UD) part-of-speech tag.
- XPOSTAG: Language-specific part-of-speech tag; underscore if not available.
- FEATS: List of morphological features from the universal feature inventory or from a defined language-specific extension; underscore if not available.
- HEAD: Head of the current word, which is either a value of ID or zero (0).
- DEPREL: Universal dependency relation to the HEAD (root if HEAD = 0) or a defined language-specific subtype of one.
- DEPS: Enhanced dependency graph in the form of a list of HEAD-DEPREL pairs.
- MISC: Any other annotation.
MTAAC additional description of these fields:
- LEMMA: Lemma to which the token should be associated
- UPOSTAG: Universal dependencies POS tag, based on a mapping between the ETCSRI POS and the UD POS
- FEATS: Unimorph tags, in order of morpheme appearance
- DEPS: will not be used at this time
You can download cdli text annotations directly in the CoNLL-U format or use our converter from CDLI-CoNLL to CoNLL-U.
Use the drop down to choose the right tool on our Conver annotate or translate page https://cdli.earth/resources/tools. You can also use our converter locally, you can download it from here: https://github.com/cdli-gh/CDLI-CoNLL-to-CoNLLU-Converter
Tags
Morphology
MTAAC has adapted a set of 92 morphological tags (28 nominal tags, 57 finite verbal tags, 7 non-finite verbal tags) from the Electronic Text Corpus of Sumerial Royal Inscriptions Project (ETCSRI), with modifications. For the full list of these tags, visit the ETCSRI Project at ORACC.
The following nine morphological tags deviate from that found at ETCSRI and are specific to the MTAAC project:
| ETCSRI | MTAAC | |
|---|---|---|
| Finite Verbal Stem | STEM | V |
| Finite Plural Stem | STEM-PL | V.PL |
| Finite Reduplicated Stem | STEM-RDP | V.RDP |
| Non-finite Verbal Stem Abolsute | STEM.ABS | NF.V.ABS |
| Non-finite Verbal Stem Preterite | STEM.SUB | NF.V.PT |
| Non-finite Verbal Stem Present-Future | STEM.PF | NF.V.F |
| Non-Finite Plural Stem | STEM-PL | NF.V.PL |
| Non-Finite Reduplicated Stem | STEM-RDP | NF.V.RDP |
| Non-Finite Present-Future Stem | STEM-PF | NF.V.PF |
The ETCSRI morphological tagging is very explicit and consists of three different attributes:
- The morpheme column based on logical table of possible suites of morphemes
- The usage of the morphemes
- The normalized form of the text
Attributes 2 and 3 are used in our CoNLL-U annotation in a hybrid attribute while the notation of the positoning of the morphemes is ommitted. For example, consider this clause:
iri-kug-ga-ka-ni
In ETCSRI, it is encoded as such:
N1=Irikug.N5=ak.N3=ani.N5=ø N1=NAME.N5=GEN.N3=3-SG-H-POSS.N5=ABS Irikug.ak.ani.ø
While in MTAAC, the equivalent is:
| FORM | SEGM | XPOSTAG |
|---|---|---|
| iri-kug-ga-ka-ni | Irikug[1]-ak-ani[-ø] | SN.GEN.3-SG-H-POSS.ABS |
We explicitly add missing morphemes in square brackets. For instance:
nin-a-ni
becomes
| FORM | SEGM | XPOSTAG |
|---|---|---|
| nin-a-ni | nin[lady]-ani[-ra] | N.3-SG-H-POSS.DAT-H |
The morphological tags are explicit and give information not only about the morpheme at hand but hint at the construction of the whole verbal chain. Eg:
| morpheme | tag | meaning |
|---|---|---|
| enden | 1-PL-A | first person plural agent suffix |
| enden | 1-PL-S | first person plural subject suffix (df) |
| enden | 1-PL | first person plural suffix in plural transitive preterite verbal forms |
Or they give indications about subtleties in meaning:
| morpheme | tag | meaning |
|---|---|---|
| e | DAT-NH | non-human dative case-marker |
| e | L3-NH | non-human locative3 case-marker |
Named Entities
Most ORACC Named Entities tags are used at CDLI. See below for a comparison chart with ETCSL.
ORACC: http://oracc.museum.upenn.edu/doc/help/languages/propernouns/index.html ETCSL: http://etcsl.orinst.ox.ac.uk/edition2/etcslhelp.php#propernouns
| ORACC | ETCSL | ||
|---|---|---|---|
| DN | Divine Name | DN | divine name |
| EN | Ethnos Name | EN | ethnic name |
| GN | Geographical Name* | GN | geographical name |
| MN | Month Name | MN | month name |
| ON** | Object Name | ON** | other name |
| PN | Personal Name | PN | personal name |
| RN | Royal Name | RN | royal name |
| SN | Settlement Name | SN | settlement name |
| TN | Temple Name | TN | temple name |
| WN | Watercourse Name | WN | watercourse name |
| AN | Agricultural (locus) Name | ||
| CN | Celestial Name | ||
| FN | Field Name | ||
| LN | Line Name (ancestral clan) | ||
| QN | Quarter Name (city area) | ||
| YN | Year Name |
* Lands and other geographical entities without their own tag. ** Note the different usages of the ON tag.
Part of Speech (POS) tags
ORACC / ETCSRI tags
ORACC POS are used at CDLI. See below for a comparison chart with other systems.
ORACC: http://oracc.museum.upenn.edu/doc/help/languages/akkadian/index.html ETCSL: http://etcsl.orinst.ox.ac.uk/edition2/etcslhelp.php#pos UD: http://universaldependencies.org/docs/en/pos/all.html Penn: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
| ORACC | ETCSL | UD | Penn Treebank POS | |||||
|---|---|---|---|---|---|---|---|---|
| AJ | adjective (including statives) | AJ | adjective | ADJ | adjective | JJ | Adjective | 7 |
| JJR | Adjective, comparative | 8 | ||||||
| JJS | Adjective, superlative | 9 | ||||||
| AV | adverb | AV | adverb | ADV | RB | Adverb | 20 | |
| RBR | Adverb, comparative | 21 | ||||||
| RBS | Adverb, superlative | 22 | ||||||
| NU | number | NU | numeral | NUM | Numeral | CD | Cardinal number | 2 |
| CNJ | conjunction | C | conjunction | CONJ | coordinating conjunction | CC | Coordinating conjunction | 1 |
| DET | determinative pronoun | PD | pronoun/determiner | DET | determiner | DT | Determiner | 3 |
| EX | Existential there | 4 | ||||||
| FW | Foreign word | 5 | ||||||
| J | interjection | I | interjection | INTJ | interjection | UH | interjection | 26 |
| LS | List item marker | 10 | ||||||
| NNS | Noun, plural | 13 | ||||||
| N | noun (including statives) | N | noun | NOUN | Noun | NN | Noun, singular or mass | 12 |
| PART | particle | PRT | particle | (chunk tags) | ||||
| PRP | Personal pronoun | 18 | ||||||
| POS | Possessive ending | 17 | ||||||
| PP | possessive pronoun | PRP$ | Possessive pronoun | 19 | ||||
| WP$ | Possessive wh-pronoun | 35 | ||||||
| PDT | Predeterminer | 16 | ||||||
| SCONJ | subordinating conjunction | IN | Preposition or subordinating conjunction | 6 | ||||
| NNPS | Proper noun, plural | 15 | ||||||
| PROPN | Proper noun | NNP | Proper noun, singular | 14 | ||||
| SYM | symbol | SYM | Symbol | 24 | ||||
| TO | to | 25 | ||||||
| VBZ | Verb, 3rd person singular present | 32 | ||||||
| V | verb (including infinitives, marked with EPOS 'N and gerundive GW) | V | verb | VERB | Verb | VB | Verb, base form | 27 |
| VBG | Verb, gerund or present participle | 29 | ||||||
| VBP | Verb, non-3rd person singular present | 31 | ||||||
| VBN | Verb, past participle | 30 | ||||||
| VBD | Verb, past tense | 28 | ||||||
| WRB | Wh-adverb | 36 | ||||||
| WDT | Wh-determiner | 33 | ||||||
| WP | Wh-pronoun | 34 | ||||||
| ADP | adposition | |||||||
| AUX | auxiliary verb | |||||||
| IP | independent/anaphoric pronoun | |||||||
| DP | demonstrative pronoun | |||||||
| MOD | modal, negative, or conditional particle | MD | Modal | 11 | ||||
| PRP | preposition | |||||||
| QP | interrogative pronoun | |||||||
| RP | reflexive/reciprocal pronoun | |||||||
| REL | relative pronoun | |||||||
| SBJ | subjunction | |||||||
| XP | indefinite pronoun | |||||||
| NEG | negator | |||||||
| PUNCT | punctuation | |||||||
| X | Other |
For a full description of the morphological annotation system, see the ETCSRI website.
ETCSL tags
For reference we add here further information regarding the ETCSL Morphological tags. The ETCSL morphological tags mostly give a normalization that can then be treated with rules to disambiguate meaning. Exception is made for the verbal bases which are explicitly identified (aspect, plural, etc). See the ETCSL
Some examples:
| POS | form | normalized |
|---|---|---|
| N | kur-kur-ra-gin7 | L,ak.gin |
| N | cag4-gada-la2-be2-e-ne | L,bi.ene |
| V | L,ani.ak | hul2-la-ni-a |
| V | mu.ra.I.n:L | e-ri-in-bar-re-ec |
| V | ga.V.n.ci:L | ga-an-ci-gen |
| V | ha.ba.NI.n:L | ha-ba-ni-in-dug4 |
The tags seem only to appear on words that display affixes (the absolutive is not marked).
See Creating Tools for Morphological Analysis of Sumerian by Tablan, Peters, Maynard and Cunningham (2006).
Syntax
For a very detailed guide on syntax annotation, see https://cdli-gh.github.io/annodoc/
Semantics
For now, semantic data is not stored in the linguistic annotations and as we develop the lexical extension of cdli, it should be even less necessary to store this sort of information in the annotations (but could however be exported in that format if useful). At this time, we are developping a light system of semantic annotation which is stored in the MISC column and consist of these elements:
- role (for professions and titles)
- unit (for any type of measure unit)
- commodity:commodity_type (fish, ... )
- tax
More should be added as research progresses. Decisions regarding on storing information about the roles of individuals in relation to the verb will depend on the reliability of our syntax annotation methods. Actions in administrative texts are mapped to the verbs outside of the annotations.
Annotation cases (morphology)
Notations of time
Month names
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN(*) | iti | iti[month] | N |
| ‘in the month X’ | gu4-ra2-bi2-mu2-mu2 | Gurabimumu[1][-‘a] | MN.L1 |
(*) See Jagersma 2010, 151. Sallaberger 2000, 3.5.4 makes it clear that, grammatically, the month names should have a locative (Ur III admin. texts only lack this because they are not grammatical).
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti diri(*) | iti | iti[month] | N |
| ‘in the intercalary month’ | diri | dirig[excess] | N.L1 |
(*) Following ePSD2 which specifies that diri in this context is a noun: diri [EXCESS] N ‘excess, intercalary month’.
Date Formulae
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN-ta(*) ‘from month X’ | iti | iti[month] | N |
| masz-da3-gu7-ta | Maszdagu[1]-ta | MN.ABL |
(*) For an example of this sequence in translation see P106228. The month name iti min-esz3 occurs 1,072 times in the CDLI Ur III admin. corpus without -ta, and is explicitly written with -ta 52 times (in these 52 occurrences iti min-esz3-ta is part of the sequence under discussion). It would seem that in ‘from month X to month X’ statements, the scribes made ablative and terminative case markers explicit; month names lacking such case markers should, perhaps, be assumed to be of the iti MN[-’a] ‘in the month X’ type, with locative. For the reconstruction of the genitive after the month names, see Jagersma 2010, 251 (33); however, contradicting this (and followed here), Jagersma 2010, 697 (120) does not reconstruct a genitive in the same situation.
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN-sze3 ‘to month Y’ | iti | iti[month] | N |
| sze-sag11-ku5-sze3 | Szesagku[1]-sze3 | MN.TERM |
Example 3
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti #-kam ‘a period of # months’ | iti | iti[month] | N |
| 1(u) | 1(u)[ten] | NU | |
| 2(disz)-kam | 2(disz)[one][-ak]-am | NU.GEN.COP-3-SG |
zal ‘Time Passed’ Expressions
zal A — Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN u4 zal-la-ta(*) | iti | iti[month] | N |
| ‘from month X, # days passed’ | ezem-{d}nin-a-zu | ezem-Ninazu[1] | MN |
| u4 | ud[day] | N | |
| 1(u) 8(disz) | 1(u) 8(disz)[one] | NU | |
| zal-la-ta | zal[pass]-a-ta | NF.V.PT.ABL |
(*) The sequence seems to be a variant of the basic ‘from month X, to month Y’ temporal expression. Examples occur in CDLI: P101388, P102524, P105222. For analysis, see Jagersma 2010, 250 (28).
zal A — Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN-sze4 | iti | iti[month] | N |
| ‘to month X’ | sze-sag11-ku5-sze3 | Szesagku[1]-sze3 | MN.TERM |
zal A — Example 3
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti # u4 #-kam | iti | iti[month] | N |
| ‘it is X months Y days’ | 7(disz) | 7(disz)[one] | NU |
| u4 | ud[day] | N | |
| 1(u) | 1(u)[ten] | NU | |
| 2(disz)-kam | 2(disz)[one]-ak-am | NU.GEN.COP-3-SG |
zal B1 — Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN-ta u4 # zal-la-a(*) | iti | iti[month] | N |
| ‘when out of month X day Y had passed’ | Sze-il2-la-ta | Sze-ila[1]-ta | MN.ABL |
| u4 | ud[day] | N | |
| 1(u) | 1(u)[ten] | NU | |
| zal-la-a | zal[pass]-a-`a | NF.V.PT.L1 |
(*) As discussed by Jagersma 2010, 652 (133), the written locative -a indicates that zal B1 is, in fact, a temporal clause. zal B1 contains an ablative after the month name ‘when out of the month X day Y …,’ while zal B2 (see P106456 has no ablative: ‘when day Y (of) month X …’.
zal B2 — Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN u4 3 zal-la-a(*) | iti | iti[month] | N |
| ‘when day Y (of) month X had passed’ | sze-sag11-ku5 | Szesagku[1] | MN |
(*) See the note on zal B1 above.
zal C — Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| iti MN-ta u4 #-am3 zal-la(*) | iti | iti[month] | N |
| ‘from month X, day Y which is passed’ | min-esz3-ta | Minesz[1]-ta | MN.ABL |
| u4 | ud[day] | N | |
| 5(disz)-am3 | 5(disz)[one]-am | NU.COP-3-SG | |
| zal-la | zal[pass]-a | NF.V.PT |
(*) English translation is uncertain, but based on a similar line from P131739 (line 11). The presence of final locative –‘a is doubtful for this sequence: of the 27 instances of #-am3 zal-la in the CDLI Ur III administrative corpus, none is written zal-la-a; #-am3 zal-la and zal-la-a seem to be in complementary distribution.
Year Names
Type A: final -a not written, not subordinate (no .SUB)
Zólyomi: “In type A , the clause is not subordinate, mu ‘year’ and the actual year name with the finite clause stands in apposition, like: "the movie 'Paris can wait’". In type A year names the actual year name functions as a proper name. This is also indicated by year names with a non-verbal predicate: mu amar-{d}suen lugal. Proper names as a rule drop the copula, cf. my copula book pp. 22–23 or Jagersma’s dissertation p. 718, he calls this type nominal clause.” (Gábor Zólyomi, personal communication, 3 July 2018).
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu OBJ ba-ab-du8(*) | mu | mu[year] | N |
| ‘in the year the boat of Enki was caulked’ | ma2 | ma[ship] | N |
| {d}en-ki-ka | Enkik[1]-ak[-ø] | DN.GEN.ABS | |
| ba-ab-du8 | ba-b-du[spread][-ø] | MID.3-SG-NH-L3.V.3-SG-S |
(*) On analogy with Zólyomi 2017, 217 #432, slot 11 is interpreted as 3.SG.NH.L3. See Jagersma p. 95 who sees a nominalizing -a at the end of year names. Sallaberger 2000, 3.5.4 makes it clear that, grammatically, the year names should have a nominalizing -a after the verb (Ur III admin. texts lack this only because they are not grammatical). See further Horsnell 1977. However, influencing the reconstruction here, Zólyomi does not reconstruct a nominalizing -a, see Zólyomi 2017, #251, #252, and #332; his type A does not have a subordinate (Zólyomi personal communication, 6 July 2018).
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu SN ba-du(*) | mu | mu[year] | N |
| ‘the year SN was built’ | puzur4-isz-{d}da-gan | Puzuriszdagan[1][-ø] | SN.ABS |
| ba-du3 | ba-du[build][-ø] | MID.V.3-SG-S |
(*) Note: all passive forms are formulated as intransitive verbs (Jagersma 2010, 494). Example text: P100159. Zólyomi’s type A year names do not have a subordinate (Zólyomi, personal communication, 6 July 2018). Note: Zólyomi 2017, text example #228 with S14 marked 3-SG-P, is an error; it should be 3-SG-S (Zólyomi, personal communication, 25 July 2018).
Example 3
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu us-sa X(*) | mu | mu[year] | N |
| ‘the year following X’ | us-sa | us[follow]-a | NF.V.PT |
| an-sza-an{ki} | Anzan[1][-ø] | SN.ABS | |
| ba-hul | ba-hulu[bad][-ø] | MID.V.3-SG-S |
(*) Note: all passive forms are formulated as intransitive verbs (Jagersma 2010, 494). For us-sa, see Zólyomi 2017, #48. For final -a or not: see Jagersma p. 95 who sees a nominalizing -a at the end of year names; Sallaberger 2000 3.5.4 makes it clear that, grammatically, the year names should have a nominalizing -a after the verb (Ur III admin. texts do not only because they are not grammatical). See further Horsnell 1977. However, influencing the reconstruction here, Zólyomi does not reconstruct a nominalizing -a, see Zólyomi 2017, #251, #252, and #332; his type A do not have a subordinate (Zólyomi personal communication, 6 July 2018). Note: Zólyomi 2017 text example #228 with S14 marked 3-SG-P is an error; it should be 3-SG-S (Zólyomi personal communication, 25 July 2018).
Example 4
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu RN lugal(*) | mu | mu[year] | N |
| ‘the year: RN (became) king’ | amar-{d}suen | Amar-Suen[1] | RN |
| lugal | lugal[king] | N |
(*) While this form may seem ungrammatical (‘year: RN king’), Jagersma discusses it on page 718 calling it a “clear example of a nominal clause” and “not some phrase”. Such constructions mark the first year of the reign of a king.
Example 5
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu RN lugal-ta(*) | mu | mu[year] | N |
| ‘since the year: Szu-Suen (became) king’ | {d}szu-{d}suen | Szu-Suen[1] | RN |
| lugal | lugal[-ta][king] | N.ABL |
(*) This understanding of mu RN lugal-ta follows the example in Zólyomi 2017, #332. Such constructions read ‘since the year: RN (became) king.”
Example 6
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu RN lugal-am(*) | mu | mu[year] | N |
| ‘the year: Amar-suen is king’ | amar-{d}suen | Amar-Suen[1].[-ø] | RN.ABS |
| lugal.am3 | lugal.ø.am | N.ABS.COP-3-SG |
(*) Following Jagersma 2010, 718. Note: although Zólyomi 2017 interprets copular phrases to end in null am-ø, glossed COP-3-SG-S, ETCSRI consistently has -am (no null) and glosses COP-3-SG (followed here).
Example 7
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu PN DN ba-hun(*) | mu | mu[year] | N |
| ‘the year: PN (the priest) of Inanna was hired’ | en-unu6-gal | Enunugal[1] | PN |
| {d}inana | Inana[1][-ak][-ø] | DN.GEN.ABS | |
| ba-hun | ba-hug[hire][-ø] | MID.V.3-SG-S |
(*) Note: all passives are formulated as intransitive verbs (Jagersma 2010, 494). An analysis of this year name type is not available in Zólyomi 2017 or Jagersma 2010, however, it would appear to be an abbreviated version of the year name seen in P218067: mu en-unu6-gal-an-na {d}inanna en {d}inanna ba-hun “the year: Enunugalana of Inanna, the priest of Inanna, was installed”. The genitival relation between PN and GN is frequently observed in CDLI translations of this year name “Enunugal(ana) of Inanna” and may be an example of a modifying genitive (Zólyomi 2017, 53) – some translations attempt to reconstruct the sense of the unabbreviated version: “the year: Enunugal(ana) (the priest of) Inana was hired”.
Example 8
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu RN bad3 SN mu-du3(*) | mu | mu[year] | N |
| ‘the year: Szulgi the king build the wall of the land’ | {d}szul-gi | Szulgi[1] | RN |
| lugal-e | lugal[king]-e | N.ERG | |
| bad3 | bad[wall] | N | |
| ma-da | mada[land][-ak][-ø] | N.GEN.ABS | |
| mu-du3 | mu[-n]-du[build][-ø] | VEN.3-SG-H-A.V.3-SG-P |
(*) For an analysis of a very similar year name, see Jagersma 2010, 485 (34a).
Example 9
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu us2-sa X-ta(*) | mu | mu[year] | N |
| ‘from the year X happened’ | us2-sa | us[follow]-a | NF.V.PT |
| bad3 | bad[wall][-ø] | N.ABS | |
| ba-du3-ta | ba-du[build][-ø]-ta | MID.V.3-SG-S.ABL | |
| mu X-sze3 | mu | mu[year] | N |
| ‘to the year X happened’ | ur-bi2-lum{ki} | Urbillum[1][-ø] | SN.ABS |
| ba-hul-sze3 | ba-hulu[destroy][-ø]-sze | MID.V.3-SG-S.TERM |
(*) Example text from P100764. See Jagersma 2010, 94 (45) for an analysis of a similar year name.
Example 10
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu SN u SN ba-hul(*) | mu | mu[year] | N |
| ‘year SN and SN were destroyed’ | Ki-masz{ki} | Kimasz[1] | SN |
| u | u[and] | CNJ | |
| Hu-ur5-ti{ki} | Hurti[1][-ø] | SN.ABS | |
| ba-hul | ba-hulu[destroy][-ø] | MID.V.3-SG-S |
(*) In coordinate noun phrases (featuring the coordinator u) case markings usually appear only after the last of the coordinated items, in this case, SN u SN.ABS. For an example see Jagersma 2010, 100 (84).
Example 11
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu us2-sa SN X mu us2-sa-bi(*) | mu | mu[year] | N |
| ‘the year after: the year after X happened’ | us2-sa | us[follow]-a | NF.V.PT |
| ki-masz{ki} | Kimasz[1][-ø] | SN.ABS | |
| ba-hul | ba-hulu[destroy][-ø] | MID.V.S-SG-S | |
| mu | mu[year] | N | |
| us2-sa-bi | us[follow]-a-bi | NF.V.PT.3-SG-NH-POSS |
(*) For an analysis of some of these forms see Jagersma 2010, 640 (60) and 643 (67). Jagersma reconstructs a nominalizing -a, perhaps on the basis that it appears to be written in his text example 60. However, Zólyomi 2017, 100 (121), followed here, does not reconstruct a nominalizing -a.
Example 12
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu en SN ba-hul(*) | mu | mu[year] | N |
| ‘the year: the en of Eridu was hired’ | eridu{ki} | eridu[1][-ak][-ø] | SN.GEN.ABS |
| ba-hun | ba-hun[hire][-ø] | MID.V.3.SG.S |
(*) Text example: P142818. Some variants may have PN SN ba-hul, in which case en is implied and the understanding is ‘PN (the priest) of SN was hired’. The genitive must still be reconstructed after SN. Some variants may include both PN and en: ‘PN the priest of SN was hired’. The genitive relationship between en and SN is attested seventeen times in the CDLI Ur III administrative corpus by the spellings eridu{ki}-ga and unu{ki}-ga.
Example 13
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| mu a-ra2 # SN ba-hul(*) | mu | mu[year] | N |
| ‘the year: SN was destroyed for the X time’ | a-ra2 | ara[times] | N |
| 3(disz)-kam-asz | 3(disz)-ak-am-sze | NU.GEN.3-SG-COP.TERM | |
| si-mu-ru-um{ki} | Simurrum[1][-ø] | SN.ABS | |
| ba-hul | ba-hulu[bad][-ø] | MID.V.3-SG-S |
(*) Text example: P101347P101347. The use of the sign asz to convey the terminative may seem unexpected. The unexplained -a- vowel before sze may be a reflection of the original spelling of -kam, which was -kamma; see Jagersma 2010, 260 (85).
Type B: final -a is written, subordinate (include .SUB)
Zólyomi: “In type B year names, the clause is subordinate, it functions as a relative clause modifying the head mu “year”: "The year in which the king built the temple." (Gábor Zólyomi, personal communication, 3 July 2018).
Seal Inscriptions
Royal Titulary
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| lugal an-ub-da limmu2-ba(*) | lugal | lugal[king] | N |
| ‘king of the four quarters’ | an-ub-da | anubda[quarter] | N |
| (lit.: ‘king of the quarters, four of them’) | limmu2-ba | limu[four]-bi-ak | NU.3-SG-NH-POSS.GEN |
(*) Often at CDLI, an-ub-da is segmented an ub-da. This is in the process of being updated to an-ub-da; all instances of an ub-da should be segmented an-ub-da at MTAAC. This brings treatment of this sequence in line with ePSD (anubda[quarter]), BDTNS, and Zólyomi 2017, 73 (83).
The Sumerian verb
| Tag | Definition |
|---|---|
| NF | Non-Finite |
| V | Verb |
| RDP | Reduplicated Stem |
| PF | Present-Future (stems with special Maru forms) |
| PL | Plural (stems with special plural forms) |
| ABS | Absolute marker (Non-Finite only) |
| PT | Preterite marker (Non-Finite only) |
| F | Future marker (Non-Finite only) |
Order of Tags Specific to the Verbal Stem for MTAAC
| 1. | 2. | 3. | 4. | 5. | 7. |
|---|---|---|---|---|---|
| NF | V | RDP | PF | PL | ABS |
| PT | |||||
| F |
Example: sub is the maru plural (PF.PL) form of verbal stem ĝen ‘to go’. Without prefixes, it is in the non-finite form; even when -ed is not written, maru forms of the stem are to be taken as being in the present future form of the non-finite (Zólyomi p. 91):
| FORM | SEGM | XPOSTAG |
|---|---|---|
| sub | sub[go][-ed] | NF.V.PF.PL.F |
ba-zi
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| ba-zi | ba-zi | ba-zig[rise][-ø] | MID.V.3-SG-S |
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| ba-an-na-zi(*) | ba-an-na-zi | ba-nna-zig[rise][-ø] | MID.3-SG-H.DAT.V.3-SG-S |
(*) See Jagersma p. 386 for the occurrence in MVN 03 257 of lu2-{d}utu-ra ba-an-na-zi ‘dispersed for Lu-Utu,’ and for his analysis of the verbal chain. This line establishes the dative relationship of Animals PN1 ba-zi as it contains a written dative -ra. Such a relationship is also indicated by ba-an-na-zi: regardless of whether -ra marks the PN, the spelling ba-an-na-zi attests to a dative resumption.
szu ti
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| PN.[e] szu ba-ti(*) | szul-e2-du3-du3-e | Szuledudu[1]-e | PN.ERG |
| ‘PN received’ | szu | szu[hand][-e] | N.L3-NH |
| ba-ti | ba[-n]-teg[accept][-ø] | MID.3-SG-H-A.V.3-SG-P |
(*) For the reconstruction of a locative 3 and the nominal element of šu ti, see Zólyomi 2017, 158.
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| PN1 + PN2 (or a group) szu ba-ab-ti(*) | PN1 | PN1[1][-e] | PN.ERG |
| ‘PN1 + PN2 received’ | PN2 | PN2[1][-e] | PN.ERG |
| szu | szu[hand][-e] | N.L3-NH | |
| ba-ab-ti | ba-b-teg[accept][- ø]] | MID.3-SG-NH-A.V.3-SG-P |
(*) An example is found in P100281. While Slot 11 may be expected to contain the human final pronominal prefix n, Jagersma 2010, 103 explains that when two persons are the subject (or a group, as in P100281), the person marker is sometimes instead the non-human -b, tag: 3-SG-NH-A. For the reconstruction of a locative 3 and the nominal element of šu ti, see Zólyomi 2017, 158.
mu-ku
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| active transitive, with ergative agent - usually MAT PN1 mu-ku | |||
| MAT PN1[-e] mu-ku(*) | mu-kux(DU) | mu[-ni][-n]-kur[enter][-ø][-‘a] | VEN.L1.3-SG- |
| ‘PN1 delivered X’ | H-A.V.3-SG-S.SUB |
(*) That mu-ku was originally verbal is borne out in the examples of ED administrative texts given in Sallaberger 2000, 2.4.1. In example 5, the sequence MAT(materials) PN mu-ku represents an active state with PN as the ergative agent ‘PN delivered the materials’. For the analysis of the verbal chain and conventions of tagging, see Zólyomi 2017, 141 (195 and 196).
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| active transitive, with ergative agent and dative participant | |||
| usually MAT PN1[-e] PN2[-ra] mu-ku, or possibly, MAT PN1[-e] mu-ku PN2[-ra] | |||
| MAT PN1[-e] PN2[-ra] mu-ku(*) | mu-kux(DU) | mu[-nna][-ni][-n]-kur[enter][-ø][-‘a] | VEN.3-SG-H.DAT.L1.3-SG- |
| ‘PN1 delivered X for PN2’ | H-A.V.3-SG-S.SUB |
(*) That mu-ku was originally verbal is borne out in the examples of ED administrative texts given in Sallaberger 2000, 2.4.1. In example 6, the sequence MAT(materials) PN1[-e] mu-ku PN2[-ra] represents an active transitive verb with PN1 as the agent (the supplier) and PN2 as the dative participant. This analysis is echoed in a recent translation of an Ur III administrative text which features a MAT PN1 mu-ku PN2 sequence, translated: ‘MAT (from) Ea-Bani; delivery (for) Sulgi-simtum’ (Liu 2015, 216 #2, AuOR 33). The ergative is reconstructed after re-verbalization. For the analysis of the verbal chain and conventions of tagging, see Zólyomi 2017, 141 (195 and 196).
Other Verbs: Finite
dug
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| bi2-in-du11(*) | bi2-in-du11 | b-i-n-dug[speak][-ø] | 3-NH.L3.3-SG-H-A.V.3-SG-P |
(*) For example, see P100065. The verb dug ‘to speak’ is here acting as a transitive verb, see example Zólyomi 2017, 215 (424). /b-i/ in slot 5 and 10 respectively can reference a verbal participant in locative 2 (Zólyomi 2017, 85). Note that while -i is sometimes mistakenly labelled L2, it is properly labeled L3 (Zólyomi 2010, 30 - although this is contradicted in several examples from the same work).
Other Verbs: Non-Finite
sug
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| su-su-dam(*) | su-su-dam | sug-sug[replace]-ed[-ø]-am | V.NF.RDP.PF.ABS.COP-3-SG |
| example | |||
| ki PN1-ta PN2 | |||
| ‘from the account of PN1, PN2 will be repaid’ | |||
| variant | |||
| ki PN1-ta PN2-e su-su-dam | |||
| ‘PN2 is to repay X from the account of PN1’ |
(*) See example Jagersma 2010, 699 (133) for an analysis of su-su-dam. Both Jagersma and Zólyomi reconstruct a null marker before a copula (NFIN according to the former, see Jagsersma 299 (134), ABS according to the latter). For a translation of the example clause, see P111930. For the variant with ergative (which occurs in P100107 see Jagersma 2010, 700 (139). Despite the presence of an ergative, the verb is still a non-finite, the copula is intransitive.
du
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| du(*) ‘will come/go’ | du | du[go][-ed] | NF.V.PF.F |
(*) Example text: P100148. This non-finite occurs in the CDLI corpus with the writings du and also du-a. Because du is the maru form of gen ‘to go,’ a present-future tense may be suspected for the form. Jagersma 2010, 627 indicates that all non-finite present-future forms are consistently marked with the -ed suffix, with the exception of the irregular verb du (-ed must therefore be reconstructed). See also Zólyomi p. 91, where he states that a present-future form will employ the maru form of the verb if there is one; therefore, the maru stem (PF) occurs in a non-finite present-future form (NF.V.PF.F). Jagersma 2010, 631 indicates that an ergative participant may or may not occur in these non-finite forms (when present there is an active sense, when absent there is a passive sense).
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| PN1 PN2-da du | ur-{gesz}gigir | Urgigir[1][-e] | PN.ERG |
| ‘PN1 will come/go with PN2’ | ra2-gaba-da | ragaba[rider]-da | N.COM |
| du | du[go][-ed] | NF.V.PF.F |
Example 3
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| kaskal PN SN-sze du-ni(*) | kaskal | kaskal[way][-sze] | N.TERM |
| ‘for the campaign, his going to SN’ | ka5-a | Ka’a[1] | PN |
| sukkal | sukkal[secretary] | N | |
| sa-bu-um{ki}-sze3 | Sabum[1]-sze | SN.TERM | |
| du-ni | du[go][-ed]-ani | NF.V.PF.F.3-SG-H-POSS |
(*) Example from P100149. While some grammars may suggest nominalizing the entire sequence with a final -a, Zólyomi 2017 does not support a nominalizing -a. An attempt has been made here to understand this sequence in light of Zólyomi’s discussion of the nominal template on pages 37-38, especially text example 15, which features appositional noun phrases within the same nominal structure. Our sequence may be analyzed: P1kaskal-P5TERM P1PN1 P2sukkal P3[P1GN-sze P1du-P3ani]. It is not clear whether the inclusion of the non-finite is permissible, though it seems likely given Zólyomi 2017, 52 (32). For the reconstructed TERM after kaskal, see P100149 line r.5, where the terminative is actually written.
sa10 ‘will pay for/to pay for’
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| sa10-sa10-de3(*) | sa10-sa10-de3 | sa-sa[pay_for]-ed-e | NF.V.RDP.F.DAT-NH |
(*) For an analysis of similar verbal structures, see Zólyomi 2017, 100 (122), (123).
Compound Verbs
According to Zólyomi 2017, 226 the nominal element of a verbal compound is by default the patient of the verb (marked in the absolute case); however, written indicators sometimes exist that certain nominal elements were instead marked in the L3, L1, dative, terminative, or commitative cases. There is no rule to clarify this situation; each compound verb must be considered individually.(*)
(*) Karahashi 2000, 42–44 states that nominal element ki is usually in the locative -a, except ki ag2 which occurs with L3; the body part nouns used in compound verbs do not indicate case as a rule (p. 46).
Example 1
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| szu di-di(*) | szu | szu[hand][-ø] | N.ABS |
| di-di | dug-dug[transform][-ed] | NF.V.RDP.PF.F |
(*) Example P100300. Must be interpreted as a present-future: Zólyomi 2017, 91 states that a present-future form will employ the maru form of the verb if there is one. Body-part nominal elements do not exhibit case indicators (Karahashi 2000, 46), the case here is assumed to be patient (Zólyomi 2017, 226).
Example 2
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| PN.[e] szu ba-ti(*) | szul-e2-du3-du3-e | Szuledudu[1]-e | PN.ERG |
| ‘PN received’ | szu | szu[hand][-e] | N.L3-NH |
| ba-ti | ba[-n]-teg[accept][-ø] | MID.3-SG-H-A.V.3-SG-P |
(*) For the reconstruction of a locative 3 and the nominal element of šu ti, see Zólyomi 2017, 158.
Example 3
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| PN1 + PN2 (or a group) szu ba-ab-ti(*) | PN1 | PN1[1][-e] | PN.ERG |
| ‘PN1 + PN2 received’ | PN2 | PN2[1][-e] | PN.ERG |
| szu | szu[hand][-e] | N.L3-NH | |
| ba-ab-ti | ba-b-teg[accept][- ø]] | MID.3-SG-NH-A.V.3-SG-P |
(*) An example is found in P100281. While Slot 11 may be expected to contain the human final pronominal prefix n, Jagersma 2010, 103 explains that when two persons are the subject (or a group as in P100281), the person marker is sometimes instead the non-human -b. For the reconstruction of a locative 3 and the nominal element of šu ti, see Zólyomi 2017, 158.
Example 4
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| szu gi4(*) | szu | szu[hand][-ø] | N.ABS |
| gi4 | gi[repay][-ø] | NF.V.ABS |
(*) Text example: P100958. The case of the nominal element is so far uncertain, not specified in available analyses. The default absolute case is assumed (Zólyomi 2017, 226).
Conditional Clauses (tukumbi)
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| tukumbi VERB(*) | tukum-bi | tukumbi[if] | CNJ |
| nu-la2 | nu-[n]-la[weigh][-ø][-‘a] | NEG.3-SG-NH-A.V.3-SG-P.SUB |
(*) Note that, following Jagersma 2010, 690, verbs in the tukumbi conditional clause should be assumed to be in the hamtu, not maru form: “Conditional clauses with tukum-bé ‘if’ contain, as a rule, a verbal form in the perfective (and not the imperfective, as with u4-da) and are followed by a main clause with an imperfective or modal form.” The tag CNJ is listed at the bottom of the ETCSRI ‘Glossing’ page.
Copular Enclitics on Verbal Chains
| Context | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| N Non-Finite-am(*) | nam-erim2-be2 | namerim[oath]-be[-ø] | N.3-SG-NH-POSS.ABS |
| ku5-ru-dam | kur[cut]-ed[-ø]-am[-ø] | NF.V.PF.ABS.COP-3-SG |
(*) This clause is intransitive with the subject (‘oath’) marked in the absolute, see Jagersma 2010, 699. Jagersma tends to reconstruct a null marker before copulas, calling it NFIN; see Jagsersma 299 (134). Zólyomi reconstructs a null before copulas, calling its ABS: ø-am or ABS.COP-3-SG. On searching ETCSRI, of the 276 instances of the copula -am (search: COP-), 249 are marked as having a preceding ABS (search: N6=COP-). Note also, while Zólyomi’s 2017 grammar consistently reconstructs ø-am-ø (ABS.COP-3-SG-S), ETCSRI seems to reconstruct ø-am ABS.COP-3-SG instead.
The Slot System
Adapted from: [/publications/1776107](Zólyomi 2017), table 6.1, 78-79 (S11-S15), 79-80 (S5-S10), 145-163 (S2-S5); “parsing” from http://oracc.museum.upenn.edu/etcsri/parsing/index.html.
Slot 1
Negative particle (nu); modal prefix (ha); prefix of anteriority; stem (in imperative forms).
-
finite marker i- assimilates with vowel of the negative particle -nu, resulting in a long ū
-
occasionally the vowel of -nu assimilates to a following syllable
-
before /ba/ the negative particle becomes -la (/publications/1776107)
-
the finite -I contracts with modal ha to become he, written HE2
-
ha may indicate an epistemic ‘it is possible’ or – stronger – ‘it is a certainty’ (negated with /na(n)/ and /bara/ respectively)
-
ha may instead express the deontic modality ‘may he ...’
-
intransitive verbs prefixed by ha occur in hamtu, transitive in the maru (/publications/1776107)
-
the prefix of anteriority -u indicates that a verb occurs prior to a second action in the sentence
-
vowel u may assimilate to the vowel of prefix -ni (but not -nni) (/publications/1776107)
| nu | negative prefix | NEG | CF | verbal stem | STEM |
| ha | modal1 prefix | MOD1 | CF | plural verbal stem | STEM-PL |
| u | prefix of anteriority | ANT | CF | reduplicate verbal stem | STEM-RDP |
Slot 2
Finite-marker prefix; modal prefixes 2-7.
-
finite marker -al only occurs when no other prefixes are between it and the verbal stem
-
finite markers occur only in front of verbal chains that would other otherwise start with a doubled consonant -mm or -nn
-
finite markers i and a may be lengthened to ii and aa in compensation for a syncopated vowel in S10 loc1 or loc2 (/publications/1776107)
-
bara- (maru agreement) forms the negative of ga and strong ha ‘I will not’ and ‘absolutely not’ respectively (/publications/1776107)
-
-na(n) (maru agreement) negates deontic -ha and the imperative ‘may he not’ and ‘do not!’ respectively
-
although dimly understood, non-negative -na and -ši both seem to indicate an affirmative epistemic, i.e. ‘he indeed did X’ (/publications/1776107)
| ga | modal2 | MOD2 | i | finite marker | FIN |
| nan | modal3 | MOD3 | ii | finite marker | FIN-L1 |
| bara | modal4 | MOD4 | ii | finite marker | FIN-L2 |
| nuš | modal5 | MOD5 | a | finite marker | FIN |
| ši | modal6 | MOD6 | aa | finite marker | FIN-L2 |
| na | modal7 | MOD7 | al | finite-marker | FIN |
Slot 3
Coordinator prefix.
Notes - p. 150
- -nga coordinates the action, i.e ‘he did X and also X’
- in negation, ‘he neither did X nor X’
| nga | coordinator | COOR |
Slot 4
Ventive (cislocative) prefix.
Notes - p. 152
- -mu is reduced to -m before a vowel or before /b/
- im-ma is i(FIN) m(VEN) b(3.SG.NH) a(DAT)
Two possible uses: i) p. 82, 151: -mu indicates motion towards event/speaker/speech event or addressee; ii) p. 81, 151: -m used to form the composite adverbial dative and loc2/loc3 prefixes for first person referent: in ma- the m functions as a 1PS pronominal while the a- is the dative (slot 6).
| mu | ventive | VEN | |||
| m | ventive | VEN |
Slot 5
The middle prefix as well as the 3.SG.NH.
Notes - p. 156
- middle voice prefix ba- indicates that the actions affect the subject or his interests
Notes - p.160
- -ba may also mark a verb as passive
- the prefix im-ma may break down to i(FIN) m(VEN) ba(MID)
- -b: when slot 5 does not contain the middle prefix, it may house the initial pronominal prefix (IPP) /b/ (specifying the person, gender and number of the first in the sequence of adverbial prefixes
- combines with S7-10 to form a compound adverbial prefix
Notes - p. 81
- precludes S6 from occurring
| ba | middle prefix | MID | |||
| b | 3-S-NH | 3-NH |
Slot 6
Initial Pronominal Prefix (=IPP) specifying the person, gender and number of the first in the sequence of adverbial prefixes; combines with S7-10 to form a compound adverbial prefix (i.e. nna = nn + dat. a).
Notes - p. 163
- -nn 3PS is /nn/ before a vowel, /n/ before a consonant
- 2PS is /-r/ before a vowel, e before a consonant
| 1 | 1PS IPP /’/ | 1-SG | nn | 3PS IPP /nn/ or /n/ | 3-SG-H |
| r | 2PS IPP /r/ | 2-SG | mee | 1P plur. IPP /mē/ | 1-PL |
| e | 2PS IPP /e/ | 2-SG | nnee | 3P plur. IPP /nnē/ | 3-PL |
Slot 7
Adverbial I: dative.
Notes - p. 80
- dative -a always takes a pronominal prefix (S5-S6)
Notes - p. 167
- a noun phrase in the dative is always accompanied by a cross reference in S7
- when S7 is present, it precludes subsequent prefixes from taking a pronominal prefix (S5-S6)
- typical graphemes used are: – MA (S6 1-SG + DAT) – RA (S6 2-SG + DAT) – NA (S6 3-SG-H + DAT) – BA or MA (S5 3-NH + DAT) – ME (S6 1P + DAT) – NE (S6 3=PL + DAT)
| a | dative prefix | DAT |
Slot 8
Adverbial II: commitative prefix.
Notes - p. 80-81
- when S5 and S7 are absent, -da may take IPP - S6 to from a compound adverbial prefix
Notes - p. 173
- presence of commitative in the nominal chain requires reflection in S8
- it may assimilate with loc1 prefix becoming /di/ wr. TI
| da | commitative prefix | COM |
Slot 9
Adverbial III: ablative or terminative prefix.
Notes - p. 182
- ablative -ta is wr. TA and occasionally RA (due to rhotacization)
- an ablative is not resumed should the verbal participant be used adverbially
- it applies only to non-human object — in the case of human participants, the construction ki PN-ak-ta is used
Notes - p. 185
- -ta may also mark the instrumental ‘with/by means of’
Notes - p. 187
- -ta may further function as adnominal ablative and serve to modify another noun in the sentence
Notes - p. 191
- terminative -ši wr. ŠI, or under ‘vowel harmony’ with the next syllable, še wr. ŠE3
Notes - pp. 80-81
- when S5 and S7-S8 (-ta and -ši) are absent, may take IPP - S6 to form a compound adverbial prefix
| ta | ablative prefix | ABL |
| ši | terminative prefix | TERM |
| še | terminative prefix | TERM |
Slot 10
Adverbial IV: locative 1, locative2 or locative3 prefix.
Notes - pp. 80-81
- when S5 and S7-S9 are absent, loc2/loc3 may combine with S5-S6 to form a compound adverbial prefix
- loc1: reflects nominal case marker /’a/ — verbal prefix refers to 3S non-human participant only
Notes - p. 203
- when S11 is empty it occurs in syncopated form -n
- when S11 is occupied it occurs as -ni
- loc1: indicates movement inside something
- loc2: reflects nominal marker /ra/ (human) or /’a/ (non-human); refers to human and non-human participants; occurs as -i before consonant, /e/ after a vowel
- S6 pronominal /nn/ can combine with loc2 to form the compound adverbial prefix -ni wr. NI (not to be confused with loc1)
- when S11 is occupied syncopation reduces compounds to /n/ (human) and /b/ (non-human) — indicates movement above or on top of something, or movement to the top of someone or something
- loc3: reflects nominal marker /ra/ (human) or /e/ (non-human) — refers to human and non-human participants — occurs as /i/ before consonant, /e/ after a vowel
- forms compound -ni wr. NI with S6 and with S5 forms compound -bi wr. NE and transliterated bi2, variant wr. BI and transliterated be2 — indicates location next to someone/something, or a movement to someone/something
| ni | locative 1 | L1 | e | locative 2 | L2 |
| ni | locative 1 used as causative in OB | LOC-OB | ø | syncopated locative 2 | L2-SYN |
| n | syncopated locative 1 | L1-SYN | i | locative 3 | L3 |
| i | locative 2 | L2 |
Slot 11
Final Pronominal Prefix (=FPP); refers to agent or patient, depending on the tense, or locative3; will indicate tense and plurality.
Notes - p. 201
- S11 will be empty if the verbal form is intransitive, if it is a non-human patient in the present future, or in verbal forms containing the modal prefix /ga/ which reference the non-human patient
| 1 | 1S final pron. prefix | 1-SG-A | n | 1S pron. prefix in OB | 1-SG-A-OB |
| e | 2S final pron. prefix | 2-SG-A | b | 3S non-H pron. prefix agent | 3-SG-NH-A |
| n | 3S final pron. prefix agent | 3-SG-H-A | b | 3S non-H pron. prefix patient | 3-SG-NH-P |
| n | 3S final pron. prefix patient | 3-SG-H-P | b | 3S non-H pron. prefix in L3 | 3-SG-NH-L3 |
| n | 3S final pron. prefix in LOC3 | 3-SG-H-L3 | nnee | 3P pron. prefix patient | 3-PL-H-P |
Slot 12
The Verbal Stem.
| CF | verbal stem (df) | V | CF | reduplicated verbal stem | V.PL |
| CF | present-future stem | V-PF | CF | independent copula | COP |
| CF | plural verbal stem | V.PL | CF |
Slot 13
Present-future marker -ed (in intransitive verbs).
| ed | present-future marker | PF | |||
| en | marks plurality of S or P | PLEN |
Slot 14
Pronominal suffix (referring to Agent, Subject or Patient depending on the tense; will indicate tense and plurality).
Both P (object of transitive verb) and S (subject of intransitive verb) are in the absolutive, and are referenced with the same set of suffixes, SET B. In the tags below, 3-SG-S marks absolute (intransitive verb), 3-SG-P marks absolute (transitive verb).
| SLOT 11 | SLOT 14 | ||
| FPP | SET A | SET B | |
| SG. 1 | /’/ | -/en/ | -/en/ |
| SG. 2 | /e/ | -/en/ | -/en/ |
| SG. 3 H | /n/ | -/e/ | -/ ø/ |
| SG. 3 NH | /b/ | -/e/ | -/ ø/ |
| PL. 1 | - | -/enden/ | -/enden/ |
| PL. 2 | - | -/enzen/ | -/enzen/ |
| PL. 3 | /nnē/ | -/enē/ | -/eš/ |
From Zólyomi 2017 fig. 9.1:
| en | 1S agent suffix | 1-SG-A | enden | 1P agent suffix | 1-PL-A |
| en | 1S subject suffix | 1-SG-S | enden | 1P subject suffix | 1-PL-S |
| en | 1S patient suffix | 1-SG-P | enden | 1P in transitive preterite | 1-PL |
| en | 2S agent suffix | 2-SG-A | enzen | 2P agent suffix | 2-PL-A |
| en | 2S subject suffix | 2-SG-S | enzen | 2P subject suffix | 2-PL-S |
| en | 2S subject suffix | 2-SG-P | enzen | 2P in transitive preterite | 2-PL |
| ø | 3S h/nh subject suffix | 3-SG-S | eš | 3P subject suffix | 3-PL-S |
| ø | 3S h/nh patient suffix | 3-SG-P | eš | 3P patient suffix | 3-PL-P |
| e | 3S h/nh agent suffix | 3-SG-A | eš | 3P in transitive preterite | 3-PL |
| e | 3S h/nh in subject in OB | 3-SG-S-OB | enee | 3P agent suffix in present-future | 3-PL-A |
Slot 15
Subordinator -‘a (changes finite verb into a subordinate clause which may then function as a relative or complement clause).
| ‘a | subordinator | SUB |
Editors
- Morphological annotations are added to the CoNLL file manually using any plain text editor or a spreadsheet program.
Morphological annotation example
| #ID | FORM | SEGM | XPOSTAG |
|---|---|---|---|
| 0.1.1 | 3(u) | 3(u)[ten] | NU |
| 0.1.2 | sila3 | sila[unit] | N |
| 0.1.3 | sze | sze[barley] | N |
| 0.2.1 | a-a-kal-la | Ayakala[1] | PN |
| 0.2.2 | sagi | sagi[cup_bearer][-ra] | N.DAT-H |
| 0.3.1 | 3(u) | 3(u)[ten] | NU |
| 0.3.2 | sila3 | sila[unit] | N |
| 0.3.3 | lu2-dinger-ra | Ludingira[1] | PN |
| 0.3.4 | sagi | sagi[cup_bearer][-ra] | N.DAT-H |
| 0.4.1 | sza3-gal | szaggal[fodder] | N |
| 0.4.2 | udu | udu[sheep] | N |
| 0.4.3 | niga | niga[fattened][-ø][-sze] | N.V.ABS.TERM |
| 0.5.1 | ki | ki[place] | N |
| 0.5.2 | gu-du-du-ta | Gududu[1][-ak]-ta | PN.GEN.ABL |
| r.1.1 | kiszib3 | kiszib[seal] | N |
| r.1.2 | a-lu5-lu5 | Alulu[1][-ak] | PN.GEN |
| r.2.1 | iti | iti[month] | N |
| r.2.2 | diri | dirig[excess][-'a] | N.L1 |
| r.3.1 | mu | mu[year] | N |
| r.3.2 | si-mu-ru-um{ki} | Simurrum[1][-ø] | SN.ABS |
| r.3.3 | ba-hul | ba-hulu[destroy][-ø] | MID.V.3-SG-S |
| s1.1.1 | a-lu5-lu5 | Alulu[1] | PN |
| s1.2.1 | dumu | dumu[child] | N |
| s1.2.2 | inim-{d}szara2 | Inimsara[1] | PN |
| s1.3.1 | kuruszda | kuruszda[fattener] | N |
| s1.3.2 | {d}szara2-ka | Szara[-ak][-ak] | DN.GEN.GEN |
Annotation of Syntax
Syntax annotations can be added manually in the CoNLL file using a plain text editor or a spreadsheet software (import at tab separated value file).
For a very detailed guide on syntax annotation, see https://cdli-gh.github.io/annodoc/
Automated annotation
TODO...